Multi Column Index
다중 컬럼 인덱스는 데이터 조회 시 함께 사용되는 컬럼들의 조회 성능을 최적화하기 위해 사용된다.
각 컬럼에 개별 인덱스를 설정하는 것과 다중 컬럼 인덱스를 사용하는 것에는 차이점이 존재하는데 아래와 같다.
개별 인덱스를 각 컬럼에 설정한 경우, 데이터베이스는 쿼리 실행 시 어느 인덱스를 우선 사용할 것인지 판단한 후, 선택된 인덱스에 따라 순차적으로 검색을 진행한다. 이 과정에서 필요한 경우 여러 인덱스를 결합하여 사용할 수 있지만 추가적인 비용이 발생할 수 있다.
반면, 다중 컬럼 인덱스는 상위 컬럼의 인덱스 값에 대해 하위 컬럼의 값을 함께 저장한다. 따라서 쿼리 실행 시 어떤 인덱스를 먼저 사용할지를 판단하는 과정이 생략되고, 상위 인덱스에 의해 이미 필터링된 결과 집합에서 하위 인덱스의 조건을 빠르게 적용할 수 있다.
결과적으로, 다중 컬럼 인덱스는 인덱스 선택에 소요되는 오버헤드를 줄이고, 검색해야 하는 인덱스의 범위를 줄이기 때문에, 일반적으로 개별 인덱스보다 더 나은 조회 성능을 제공할 수 있다.
다중 컬럼 인덱스를 사용할 경우, 쿼리 작성 시 인덱스를 설정한 순서에 맞춰 작성하는 것이 중요하다.
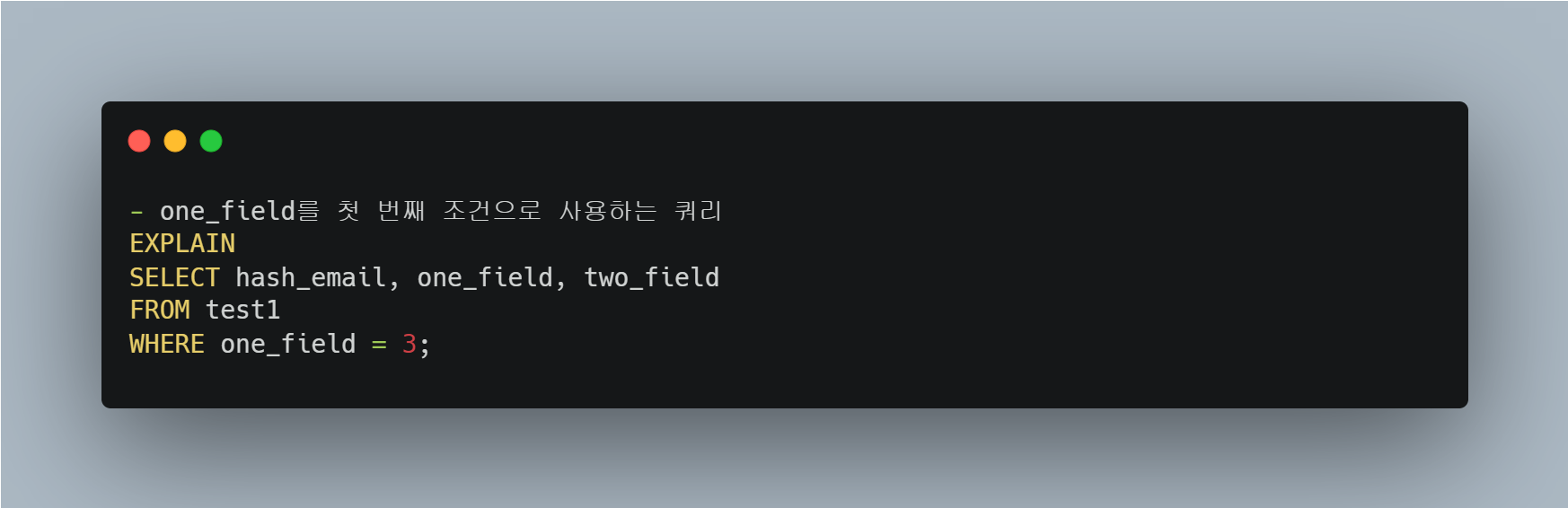
예를 들어, one_field와 two_field에 대한 다중 컬럼 인덱스를 사용할 때, 이 인덱스는 one_field를 첫 번째 조건으로 사용하는 쿼리에서 활용된다.
테스트를 위해 예제 테이블을 아래의 SQL문을 사용해 생성한 뒤, Insert 쿼리로 데이터를 삽입하자.
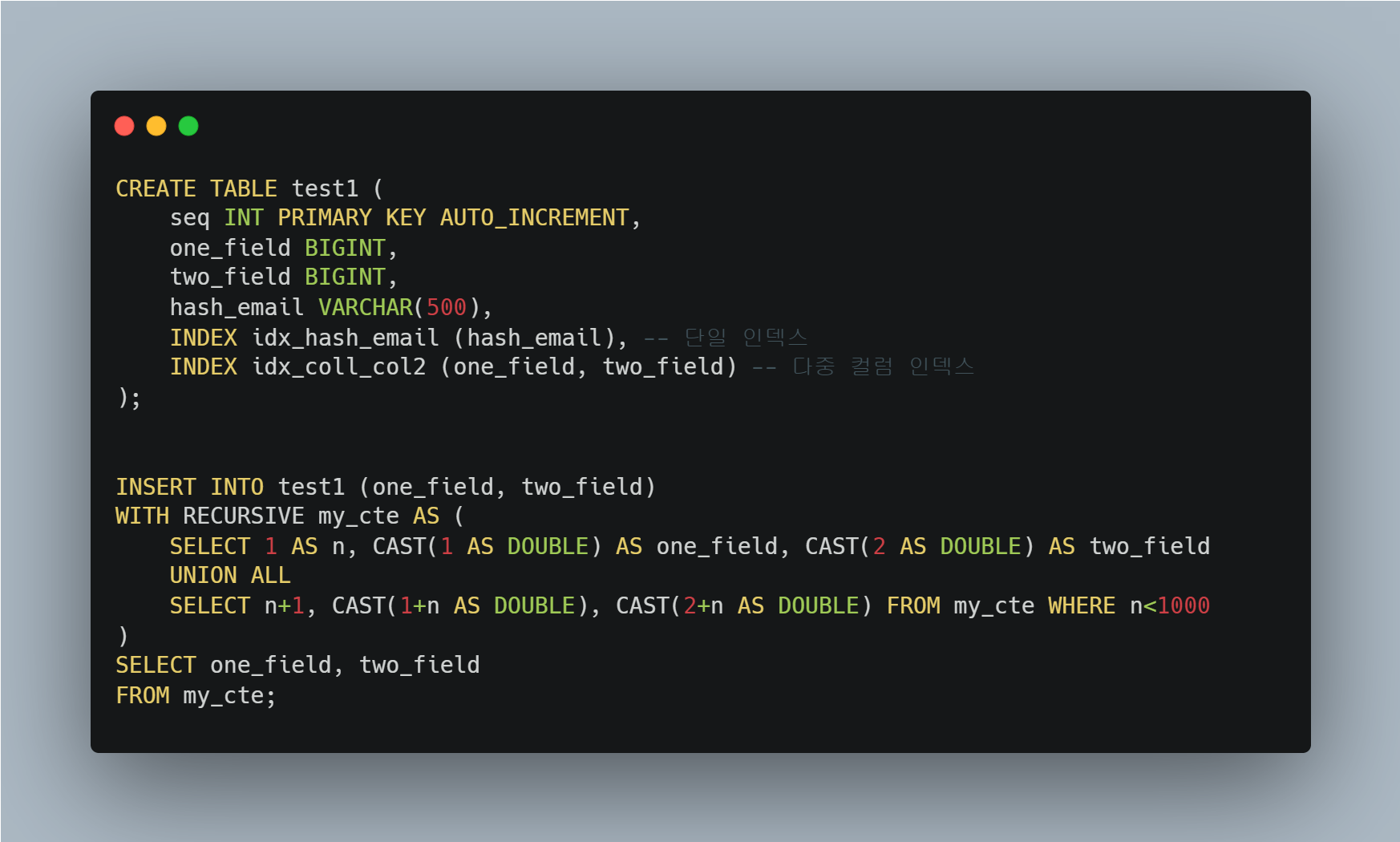
다음으로, EXPLAIN 명령어를 통해 쿼리 실행 계획을 확인해 보자.
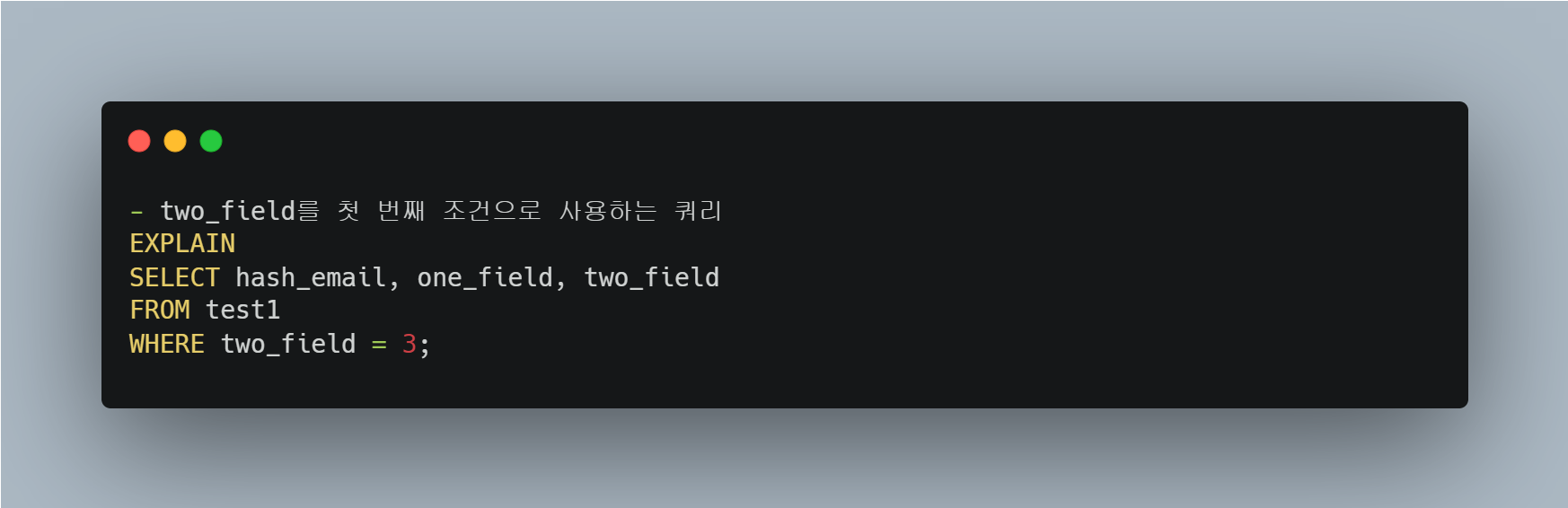
two_field를 첫 번째 조건으로 사용하는 쿼리는 "테이블 풀 스캔"이 수행된다.

one_field를 첫 번째 조건으로 사용하는 쿼리는 "인덱스 검색"이 수행된다.

또한, 테이블에 설정된 인덱스를 확인하려면 다음 쿼리를 사용할 수 있다.
아래 쿼리를 통해 카디널리티가 높은 컬럼을 확인할 수 있다. 해당 값을 확인한 후 카디널리티가 높은 컬럼의 인덱스를 선두에 배치하면 좋다.


이와 같은 다중 컬럼 인덱스는 적절하게 사용될 경우, 복잡한 데이터 조회 시 효율적인 검색 성능을 제공할 수 있다.
다만, 다중 컬럼 인덱스를 설정할 때는 인덱스 순서를 고려하여 쿼리를 작성하자.
Covering Index
MySQL에서 Covering Index는 특정 쿼리를 실행할 때, 쿼리의 모든 필요한 데이터를 인덱스 자체에서 바로 얻을 수 있는 경우를 의미한다. 즉, 데이터베이스에서 테이블의 실제 데이터 블록에 접근하지 않고도, 인덱스만으로 쿼리 결과를 제공할 수 있는 인덱스다.
아래 쿼리는 `email`과 `name` 컬럼에 복합 인덱스를 생성하여, Covering Index를 구성했다.
이러한 인덱스는 쿼리가 테이블의 실제 데이터 블록에 접근하지 않고도 인덱스만으로 필요한 데이터를 조회할 수 있게 한다.

아래 쿼리는 `email`과 `name` 모두 인덱스에 포함되어 있으므로, 이 쿼리는 인덱스만으로 실행된다.
따라서, 이 인덱스는 Covering Index로 동작한다.


결론적으로, 커버링 인덱스는 쿼리가 요구하는 모든 데이터를 인덱스 자체에서 얻을 수 있게 해주는 인덱스다. 실무에서는 지속적으로 변화하는 요구사항에서 유지하기 어려운 방법이긴 하지만 사용할 수 있으면 사용하는 게 좋다.
ORDER BY
MySQL에서 ORDER BY 절은 결과를 특정 기준에 따라 정렬하는 데 사용된다.
생각보다 ORDER BY 절이 복병인 게 ORDER BY 절에서 사용하는 컬럼에 대해 인덱스가 설정되어있지 않으면
Filesort라는 별도의 정렬 작업을 수행하게 되어 대량의 데이터를 다룰 때 쿼리 성능이 저하될 수 있다.
Filesort란 무엇인가?
Filesort는 MySQL이 ORDER BY 절을 처리하는 두 가지 방법 중 하나다. 인덱스를 사용하지 못할 때 MySQL은 Filesort를 사용하여 결과를 정렬하는데 이 과정에서 메모리와 디스크를 사용한다.
Filesort는 두 가지 방식으로 동작하는데 다음과 같다.
| 메모리 내 정렬 | 디스크 기반 정렬 |
| - 정렬해야 할 데이터가 sort buffer(소트 버퍼)에 모두 수용될 수 있는 경우, MySQL은 메모리에서만 정렬 작업을 처리한다. - 이 경우, 성능 저하는 크지 않을 수 있다. |
- 정렬해야 할 데이터가 sort buffer의 크기를 초과하면, MySQL은 데이터를 여러 조각으로 나누어 디스크에 임시로 저장한다. - 이 과정에서 디스크 I/O가 발생하며, 쿼리 성능이 크게 저하됩니다 |
MySQL은 정렬을 수행하기 위해 별도의 메모리 공간을 할당받아 사용한다.
- 이 메모리 공간을 sort buffer라고 한다.
Filesort 정렬은 무엇이 문제인가
정렬해야 할 레코드가 적어서 메모리에 할당된 sort buffer만으로 정렬할 수 있다면 빠르게 정렬이 되겠지만, 하지만 정렬해야 할 레코드의 수가 sort buffer로 할당된 공간보다 많다면 얘기는 달라진다.
MySQL은 정렬해야 할 레코드를 여러 조각으로 나눠서 처리하는데, 이 과정에서 임시 저장을 위해 디스크를 사용한다.
즉, 이러한 작업들은 모두 디스크 I/O를 발생시킨다.

| 동작 과정 | |
| Data Scan | - 디스크에서 정렬할 데이터를 읽어 Sort Buffer에 로드 |
| Sort Buffer | - Sort Buffer에서 정렬 가능한 데이터는 메모리 내에서 정렬 - sort_buffer_size 내에서 처리 |
| Temp File | - Sort Buffer의 크기를 초과하는 데이터는 디스크의 Temp File로 분할 저장 - 여러 임시 파일에 정렬된 데이터 조각이 저장됨 |
| Multi-merge | - Temp File들을 병합하여 하나의 Result File로 생성 -> 디스크 I/O 발생 |
| Read Random Buffer | - 병합된 결과를 디스크에서 읽어 Read Random Buffer에 저장 |
| Result Set: | - 최종적으로 정렬된 데이터가 Result Set으로 반환 |
Filesort의 성능 문제와 해결 방법
가장 좋은 방법은 ORDER BY 절에서 사용하는 컬럼에 대해 인덱스를 설정하는 것이다. 그러면 MySQL은 인덱스를 통해 정렬을 수행하게 되어 Filesort를 피할 수 있다.
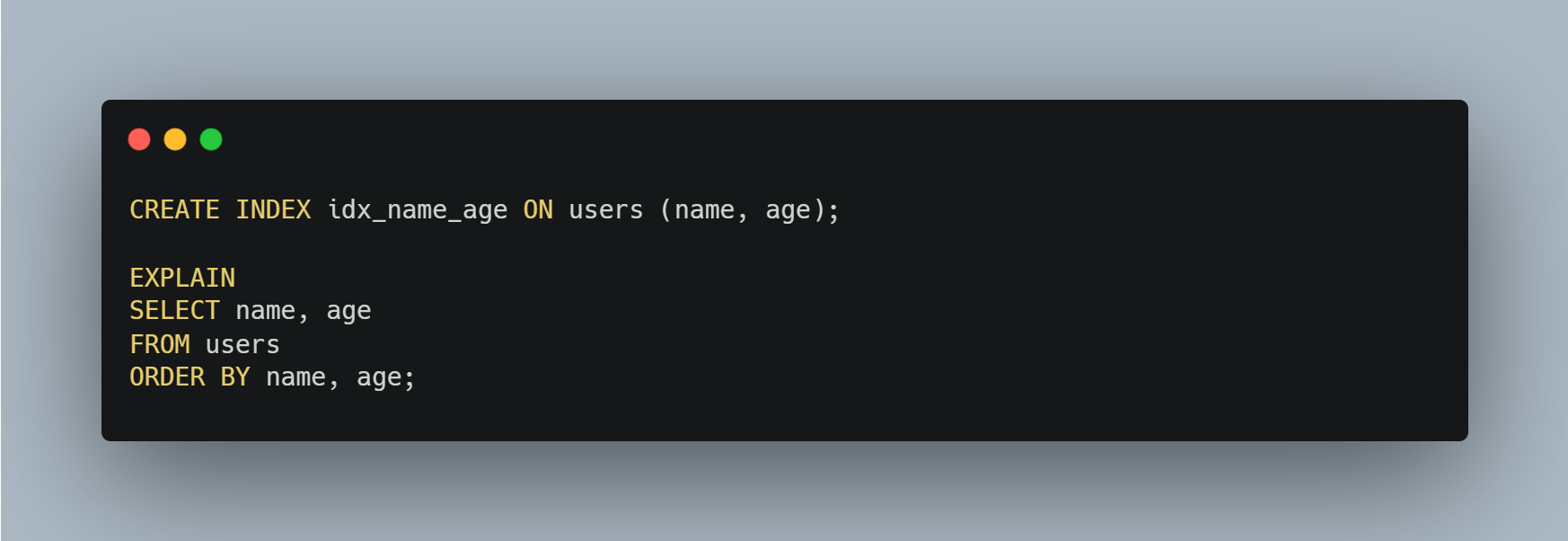
주의해야 할 점은 복합 인덱스를 사용할 경우, ORDER BY 절에서 사용된 컬럼 순서와 인덱스 정의 순서가 일치해야 된다는 점이다.
아래 쿼리에서는 `name`과 `age`에 대해 인덱스가 설정되어 있어 Filesort를 피할 수 있다.
또 다른 방법으로는 `sort_buffer_size` 시스템 변수를 조정해 sort buffer의 크기를 증가시키는 방법이 있다.
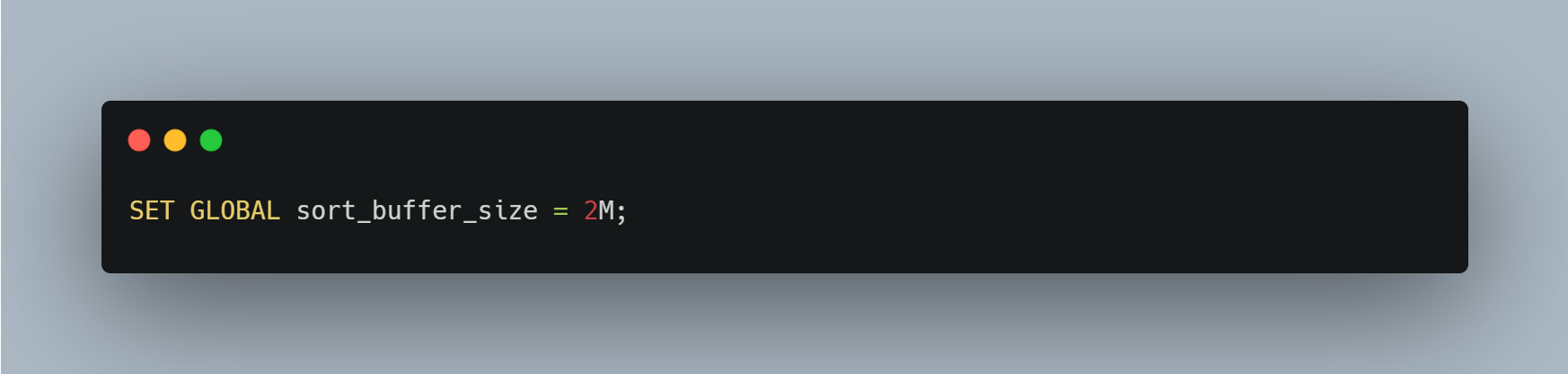
그러나 시스템 변수를 조정해 Filesort를 피하기보다는 적절한 인덱스를 설정해 피하는 것이 더 적합해 보인다.
INSERT
보통 쿼리 성능 개선에 고민할 때 조회 쿼리 위주로 생각하게 된다. 그러나 대량의 데이터를 삽입하는 INSERT 쿼리에 대해서도 알아야 다른 트랜잭션의 성능을 저하시키지 않을 수 있다.
Bulk Insert
MySQL에서 대량의 데이터를 삽입할 때, 일반적으로 여러 번의 INSERT 문을 사용하는 것은 비효율적이다. 각 INSERT 문은 데이터베이스와의 연결(Connection)을 발생시키며, 이 과정에서 네트워크 오버헤드가 발생한다. 이를 해결하기 위해 Bulk Insert 기법을 활용할 수 있다.
Bulk Insert는 여러 개의 레코드를 한 번에 삽입하는 방식으로, 단일 INSERT 문에서 여러 개의 VALUES를 지정하여 실행한다. 이를 통해 데이터베이스와의 연결 횟수를 줄여 네트워크 오버헤드를 감소시킬 수 있다.

주의할 점은 `max_allowed_packet` 변수의 최대 데이터 크기를 적절하게 조정해야 한다.
default 값으로 한 번에 전송할 수 있는 데이터 패킷의 최대 데이터 크기는 1MB로 설정되어 있다.

GORM에서는 Bulk Insert를 간단하게 지원하는데 아래에 예제 코드를 참고하자.

Index Dive Using In Query
MySQL에서 인덱스가 잘 설정되어 있고, 쿼리 자체도 큰 문제가 없어 보이는데도 성능이 저하된다면, Index Dive 문제일 수 있다. 특히, IN 조건을 사용하는 쿼리에서 이러한 문제가 발생하는데 어떠한 상황에서 문제가 발생되는지 알아보자.
Index Dive란?
MySQL 서버에서 쿼리가 실행되면, 옵티마이저(Optimizer)는 통계 정보뿐만 아니라 실제 테이블의 데이터를 샘플링해서 확인 후, 최종 사용할 실행 계획을 선택한다. 이때 실제 데이터를 샘플링해서 확인하는 과정을 Index Dive라고 한다.
보통 아래와 같은 조건이면, Index Dive 과정에서 많은 CPU와 Disk I/O 자원이 소모될 수 있다.
- 많은 개수의 엘리멘트가 IN (list)에 사용되는 경우
- IN (list) 조건 자체가 여러 번 사용되는 경우
- IN (list) 조건들이 사용할 수 있는 인덱스가 많은 경우
Index Dive 과정으로 인해서 의도치 않게 많은 CPU와 Disk storage 자원이 소모되는 경우 튜닝 방법에 대해서 살펴보자.
문제 상황
MySQL 서버를 포함한 모든 RDBMS에서는 쿼리가 실행되면, 해당 쿼리의 최적 실행 경로를 찾기 위해 사용 가능한 모든 처리 방법의 예상 비용을 계산하게 된다. 여기에서 “사용 가능한 모든 처리 방법”이 중요한데.
테이블의 인덱스가 많을수록 사용 가능한 방법이 많아지게 되면서 실행 계획 수립 과정이 복잡해진다.
예를 들어, 아래 쿼리를 보자.
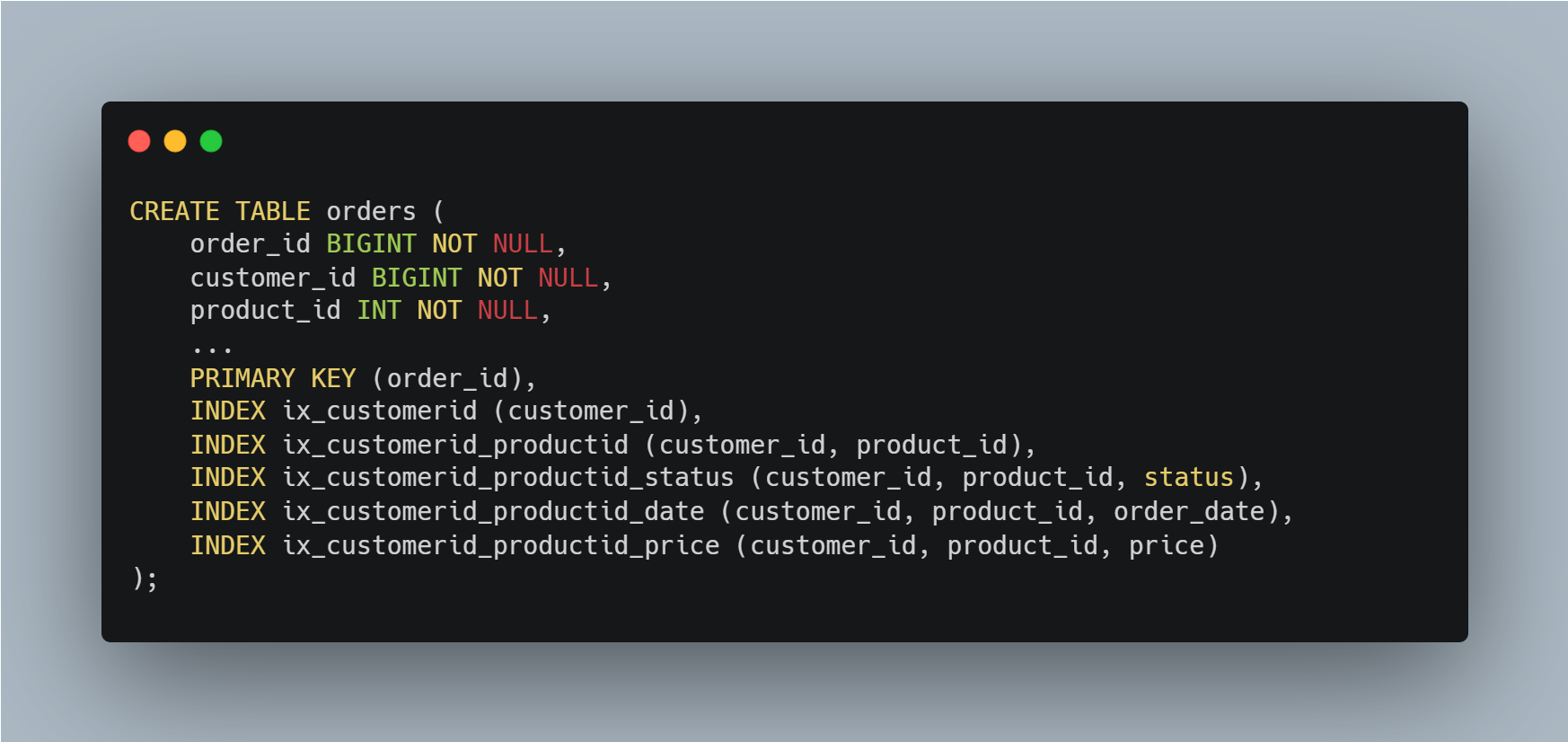
articles 테이블에 아래와 같이 2개의 IN (list) 조건을 가진 쿼리를 실행하면,
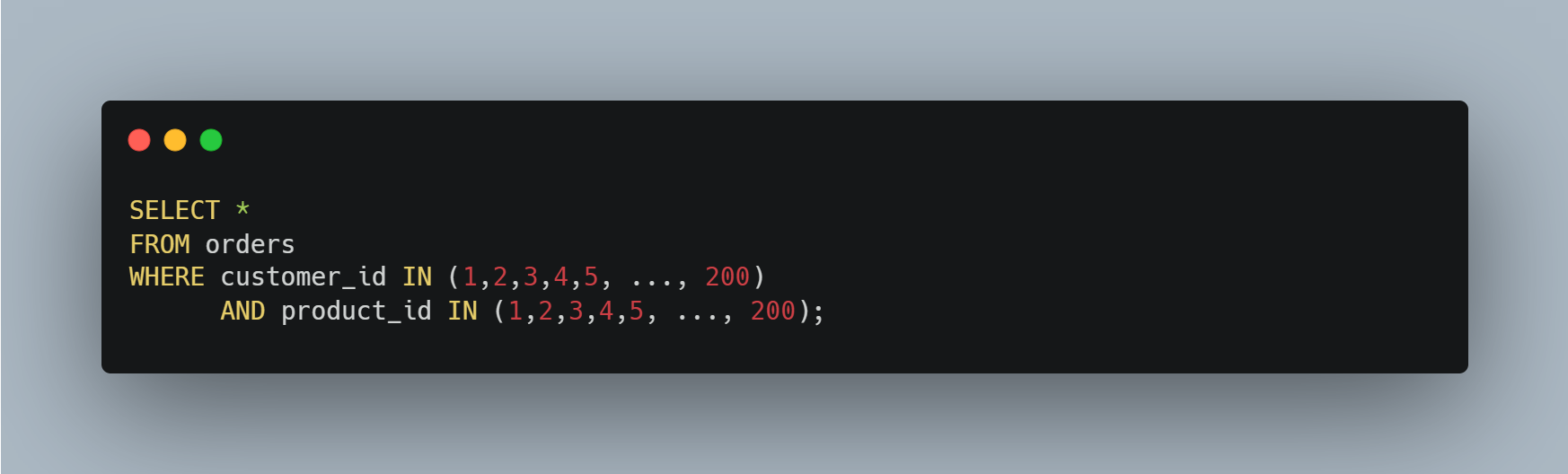
MySQL 서버는 IN (list)에 나열된 모든 값의 (customer_id, product_id) 조합에 대해 통계 정보를 수집한다.
즉, (customer_id, product_id) 조합 40000개(200 * 200)에 대해서 일치하는 레코드 건수가 몇 건이나 될지 예측하는 작업을 수행한다.
그런데 orders 테이블에는 이 쿼리를 실행하기 위해서 사용 가능한 인덱스가 5개나 되기 때문에 작업을 5번이나 반복하게 된다. 이 정도의 실행 계획 수립 과정은 실제 쿼리 실행보다는 통계 정보 수집에 더 많은 CPU나 Disk 자원이 소모된다.
쿼리 튜닝
Index Dive 과정으로 인해서 의도치 않게 많은 CPU와 Disk storage 자원이 소모되는 현상을 개선하기 위해 인덱스 개수를 줄이면 되지 않나라고 생각할 수 있다. 그러나 단순히 인덱스 수를 줄이는 것 만으로는 문제를 개선할 수 없다.
특정 인덱스가 다른 쿼리에서 사용된다면, 해당 인덱스를 쉽게 삭제할 수 없으며, 불필요한 인덱스를 제거하더라도 통계 수집에 많은 시간이 소모될 수 있다. 요약하자면 인덱스를 최소화한 이후에도 성능 문제가 여전히 존재할 수 있다는 말이다.
위와 같은 문제를 옵티마이저 힌트를 통해 개선할 수 있다.
힌트는 MySQL 옵티마이저가 특정 인덱스를 사용하도록 유도함으로써 실행 계획 수립 단계를 최소화할 수 있다. 대표적인 옵티마이저 힌트로는 세 가지가 있는데 그중 버전에 관계없이 사용할 수 있고 가장 대중화된 FORCE INDEX에 대해 알아보자.
FORCE INDEX
FORCE INDEX 힌트는 MySQL 서버가 쿼리를 실행할 때 특정 인덱스를 반드시 사용하도록 지시하는 역할을 한다.
옵티마이저가 많은 자원을 사용하는 경우를 방지하기 위해 FORCE INDEX를 사용하여 옵티마이저가 특정 인덱스를 강제로 사용하도록 유도할 수 있다.
예를 들어, 아래 쿼리를 보자.
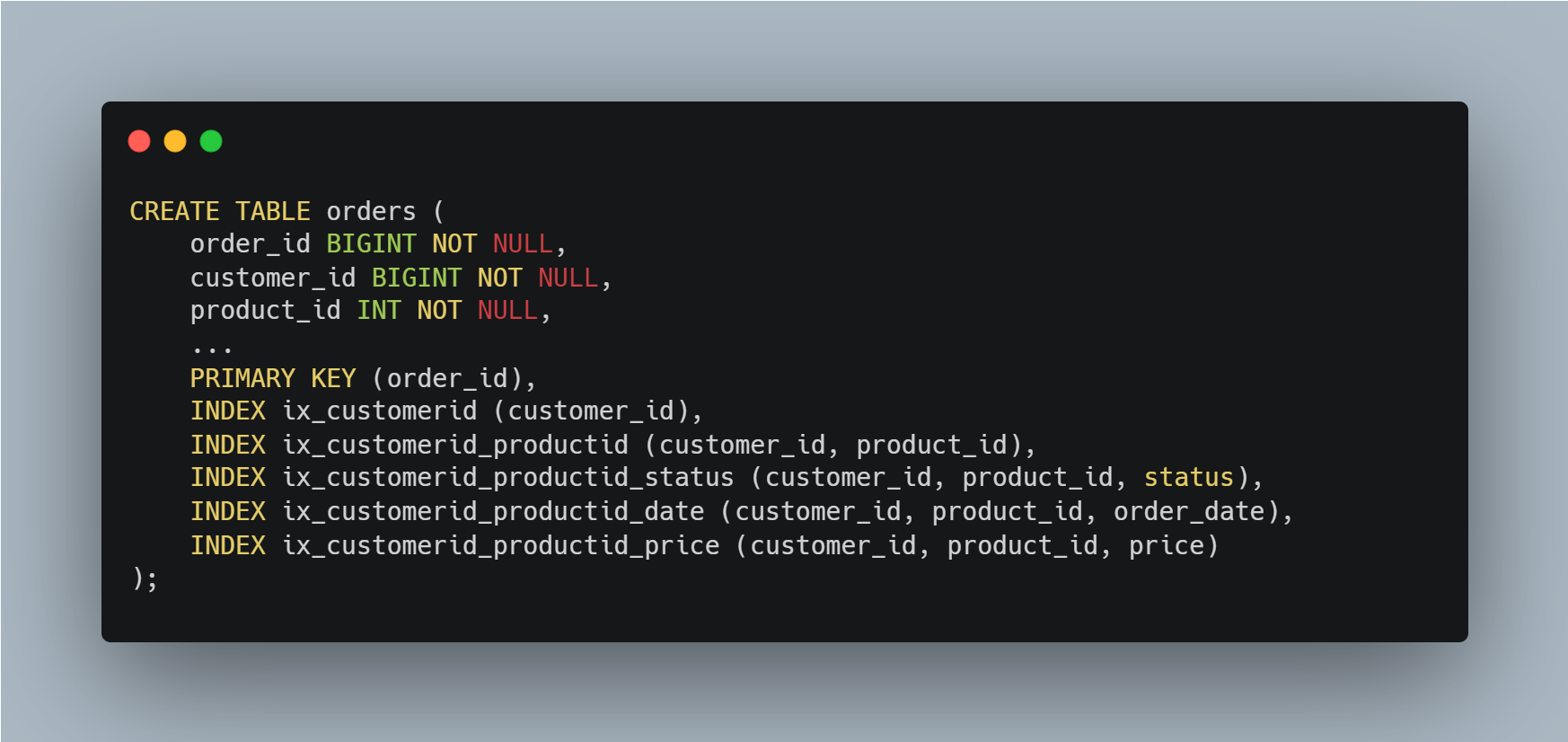

`Step 1` 쿼리는 Index Dive 과정에서 불필요한 자원 소모가 발생할 수 있는 예시 쿼리다.
`Step 1` 쿼리를 `Step 2` 쿼리처럼 FORCE INDEX 힌트를 사용하여 옵티마이저가 특정 인덱스를 강제로 사용하게 할 수 있다. FORCE INDEX를 적용하면, 옵티마이저는 반드시 ix_customerid_productid 인덱스를 사용하여 쿼리를 실행한다. 이를 통해 불필요한 인덱스 다이브 과정을 줄일 수 있다.
물론 쿼리가 FORCE INDEX 힌트에 명시하는 인덱스를 항상 사용한다는 것을 먼저 확인하고 적용해야 한다. FORCE INDEX 힌트를 사용하기 전에, 해당 인덱스가 쿼리 성능을 개선할 수 있는지 확인한 후 적용해야 한다는 말이다.
그러나 쿼리에 IN (list) 패턴이 사용된다 하더라도, 아래와 같은 경우에는 크게 걱정하지 않아도 괜찮다.
- WHERE 절에 하나의 IN (list) 조건만 사용되는 경우
- IN (list)에 사용된 엘리멘트의 개수가 많지 않은 경우
- IN (list) 조건이 인덱스를 사용하지 못하는 경우
출처
200억건의 데이터를 MySQL로 마이그레이션 할 때 고려했던 개념과 튜닝 방법 강의 | July - 인프런
July | 기존 MongoDB를 통해 관리하는 200억건의 데이터를 MySQL로 이전을 하면서 고려했던 개념들에 대해서 다루었습니다., 200억건의 데이터를 어떻게 마이그레이션 할까요?? 🤔저는 최근 실무에서 M
www.inflearn.com
Index Dive 비용 최적화. MySQL 서버의 실행계획 수립(Index Dive) 단계에서 많은… | by Sunguck Lee | 당근 테크 블로그 | Medium
Index Dive 비용 최적화
MySQL 서버의 실행계획 수립(Index Dive) 단계에서 많은 CPU와 Disk storage 자원이 소모되는 경우, 어떻게 튜닝할 수 있을까?
medium.com
[MySQL] 다중 컬럼 Index의 동작 방식 (velog.io)
[MySQL] 다중 컬럼 Index의 동작 방식
검색 성능을 개선할 수 있는 방법
velog.io
MySQL 인덱스 성능 개선하기 - 커버링 인덱스 (velog.io)
MySQL 인덱스 성능 개선하기 - 커버링 인덱스
목표페이징(Paging)을 구현하다보면 다양한 검색필터와 연관관계에 치여 슬로우 쿼리(slow query)가 발생하거나 성능 개선의 니즈를 갖게 된다. 이번 포스트는 성능 개선을 위한 커버링 인덱스를 알
velog.io
Today-I-Learn/MySQL/MySQL Filesort란 무엇일까. md at master · wjdrbs96/Today-I-Learn (github.com)
Today-I-Learn/MySQL/MySQL Filesort란 무엇일까.md at master · wjdrbs96/Today-I-Learn
:octocat: Today I Learned. 그날 그날 모든 활동들을 정리. Contribute to wjdrbs96/Today-I-Learn development by creating an account on GitHub.
github.com
Bulk Inserting - MySQL 다량의 데이터 넣기 (dwer.kr)
Bulk Inserting - MySQL 다량의 데이터 넣기
dev.dwer.kr
[TIL / 데이터관리] 한 번에 여러 데이터를 MySQL에 입력하고 싶다고? SQL Injection 이 우려된다? Prepared
우선 SQL문이 처리되는 과정은 위와 같다. 반환되는 값이 없는 `INSERT`나 `UPDATE`, `DELETE` 같은 경우는 FETCH의 과정이 생략된다. 보통의 `Statements` 같은 경우는 위와 같이 처리 된다. `Prepared Statementes`
velog.io
'Dev > DataBase' 카테고리의 다른 글
| 『DataBase』 Oracle SQL 중급 문법 (1) | 2024.11.18 |
|---|---|
| 『DataBase』 Oracle SQL 기초 문법 (2) | 2024.11.18 |
| 『DataBase』 MyBatis 문법 (0) | 2024.11.01 |
| 『DataBase』 MyBatis 내부 구조 (0) | 2024.11.01 |
| 『DataBase』 Legacy Query 성능 개선 과정 (0) | 2024.07.25 |



