Query 성능 개선이 필요했던 이유
약 28,000개의 데이터 행을 처리하는 조회 기능에서 성능 저하 현상이 발생했다. 데이터가 많지 않았기 때문에 성능 저하를 예상하지 못했다. 조회 응답 시간이 5,500ms ~ 6,000ms 정도 소요되었고, 유저 입장에서는 해당 기능이 중지된다고 느껴질 정도였다.
해당 기능은 장애 발생 시 모니터링 인원의 편의성을 위해 만들어진 것으로, 평상시 자주 사용하지는 않지만, 소 잃기 전에 외양간을 고친다는 마음으로 성능 개선을 시도했다. 총 2번의 개선 시도가 있었으며, 그 내용은 다음과 같다.
1차 개선
1. 서브 쿼리를 사용하던 기존 구조를 조인 구조로 리팩토링
2. 총행수를 계산하기 위해 전체 쿼리를 서브 쿼리로 감싸던 방식을 명시적으로 조인된 테이블에서 직접 계산하도록 리팩토링
2차 개선
1. 총 행 수 계산과 데이터 페이징을 결합하여 단일 쿼리 스코프에서 처리함으로써 데이터베이스 호출 횟수를 줄이고 쿼리 실행 시간을 단축
2. 특정 필터에 관련된 쿼리 로직에 인덱스 적용
Legacy Query 성능 개선을 위해 알아야 하는 개념
Legacy Query를 개선하는 김에 Query 개선을 위한 방법이 무엇이 있으며 기본적인 개념을 간략하게 알아보자.
Query 성능을 높이기 위해 최적화할 수 있는 포인트는 Concurrency, Throughput, Latency 3가지 포인트를 개선하면 된다.
Concurrency
- 동시에 데이터베이스에서 실행되는 쿼리 수를 의미한다.
- 워크로드가 주로 가벼운 삽입 및 테이블 업데이트인 경우 동시성은 낮다.
- 그러나 이러한 작업이 동시에 많이 발생하는 경우 전체 성능에 부정적인 영향을 미칠 수 있다.
Throughput
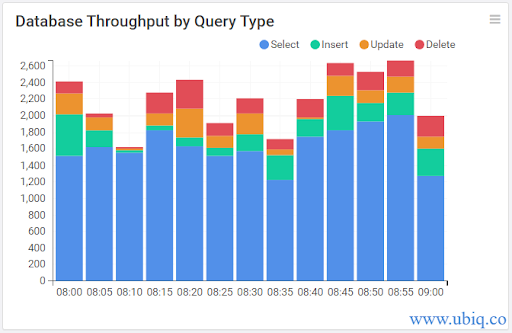
- 시간 단위당 실행되는 쿼리 수를 의미한다.
- 이는 동시성/시간 단위의 함수다. 작업 부하가 주로 테이블에 대한 가벼운 삽입 및 업데이트인 경우, 반복 컴파일을 방지하기 위해 해당 쿼리를 저장 프로시저 내에 캡슐화할 수 있다.
- 위 이미지에서 보이는 것처럼, 다양한 쿼리 타입(Select, Insert, Update, Delete)의 처리량을 시각화하여 데이터베이스의 성능을 모니터링할 수 있다. 이 방법을 통해 병목 현상을 식별하고 성능을 최적화할 수 있다.
Latency
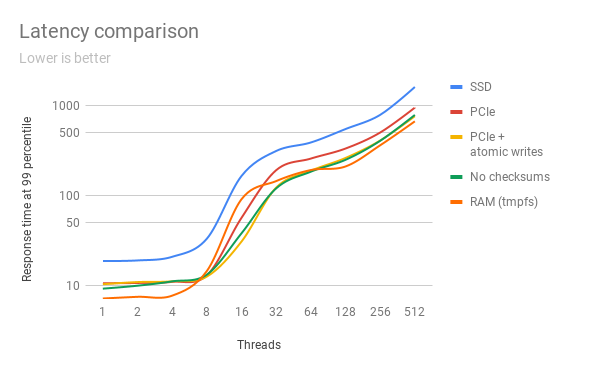
- 쿼리 실행 시간을 의미한다.
- 비즈니스 요구 사항에 적합한 데이터베이스 스키마, 테이블 유형 및 키를 선택하여 최적화할 수 있습니다.
- 데이터베이스 엔진의 제어를 벗어난 문제(예: 네트워크 연결 불량)도 대기 시간을 유발할 수 있습니다.
ETC
- 작업 공간 크기는 작업 공간의 데이터베이스 처리량과 성능을 결정한다.
- 일반적으로 크기가 클수록 쿼리 성능이 더 좋아지고 대기 시간이 짧아지며 동시 쿼리 수가 더 많아진다.
1. 쿼리에서 꼭 필요한 컬럼만 선택하여 불러오는 것이 좋다.
// 개선 전
SELECT * FROM 테이블명;
// 개선 후
SELECT id FROM 테이블명;
많은 필드 값을 불러올수록 데이터베이스는 더 많은 로드를 부담하기 때문이다.
2. 데이터베이스 컬럼의 값을 직접 비교하고, 함수나 연산을 피하는 것이 좋다.
// 개선 전
SELECT id, name
FROM 테이블명
WHERE YEAR(birth_date) = 1990;
// 개선 후
SELECT id, name
FROM 테이블명
WHERE birth_date BETWEEN '1990-01-01' AND '1990-12-31';
개선 전 쿼리는 YEAR(birth_date) = 1990 조건을 사용한다. 이로 인해 birth_date 컬럼의 모든 값을 YEAR 함수로 변환하여 비교하게 되며, 인덱스를 사용할 수 없게 되어 성능이 저하된다.
개선 후 쿼리는 함수 사용을 피하고, 인덱스를 활용할 수 있도록 조건을 변경하여 성능을 향상합니다. birth_date BETWEEN '1990-01-01' AND '1990-12-31' 조건을 사용하면 인덱스를 활용할 수 있어 쿼리 성능이 크게 개선됩니다.
3. LIKE 연산자를 사용할 때, 와일드카드 (%)는 문자열의 앞부분에 배치하지 않는 것이 좋다.
// 개선 전
SELECT COUNT(*)
FROM products
WHERE name LIKE "%Laptop";
// 개선 후
SELECT COUNT(*)
FROM products
WHERE name LIKE "Laptop%";
개선 전 쿼리는 name LIKE "%Laptop" 조건을 사용하여 name 컬럼의 모든 값을 검색한다. 이로 인해 인덱스를 사용할 수 없게 되어 전체 테이블 스캔(Full Table Scan)을 유발하여 성능이 저하된다.
개선 후 쿼리는 name LIKE "Laptop%" 조건을 사용합니다. 이 조건은 문자열의 앞부분에 와일드카드(%)가 배치되어 있어 인덱스를 사용할 수 있으며, 전체 테이블 스캔을 피할 수 있어 성능이 향상된다.
4. SELECT DISTINCT나 UNION DISTINCT와 같은 중복 제거 연산은 가능한 한 사용을 자제한다.
// 개선 전
SELECT DISTINCT e.name
FROM employees e
INNER JOIN projects p
ON e.id = p.employee_id;
// 개선 후
SELECT e.name
FROM employees e
WHERE EXISTS (
SELECT 1
FROM projects p
WHERE e.id = p.employee_id
);
개선 전 쿼리는 조인(INNER JOIN)을 통해 employees와 projects 테이블을 결합할 때, 한 명의 직원이 여러 프로젝트에 참여하고 있다면 동일한 직원 정보가 여러 번 반복된다. 이때 DISTINCT 연산자를 사용하여 중복된 직원 이름을 제거한다. 하지만 DISTINCT 연산자는 모든 결과를 정렬하고 중복을 제거하는 작업을 수행하므로, 큰 데이터셋에서 성능이 저하될 수 있다.
개선 후 쿼리는 EXISTS 연산자를 사용하여 직원이 적어도 하나의 프로젝트에 참여하고 있는지 확인한다. EXISTS 연산자는 서브쿼리가 조건을 만족하는 행을 찾으면 즉시 TRUE를 반환하므로, 중복 제거를 위한 불필요한 연산을 피할 수 있다. 이는 특히 데이터가 많을 때 성능을 크게 향상할 수 있다.
5. GROUP BY 연산을 할 때, 같은 조건이라면 HAVING 대신 WHERE 절을 사용한다.
// 개선 전
SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department
HAVING department LIKE 'Sales%';
// 개선 후
SELECT department, COUNT(*) AS employee_count
FROM employees
WHERE department LIKE 'Sales%'
GROUP BY department;
개선 전 쿼리는 GROUP BY department 후에 HAVING department LIKE 'Sales%'를 사용하여 결과를 필터링한다. HAVING 절은 GROUP BY 연산 후에 실행되므로, 불필요한 데이터가 GROUP BY 연산에 포함된다. 이와 같은 과정은 큰 데이터셋에서 성능이 저하될 수 있다.
개선 후 쿼리는 WHERE department LIKE 'Sales%'를 사용하여 GROUP BY 연산 전에 데이터를 필터링한다. WHERE 절은 GROUP BY 연산 전에 실행되므로, GROUP BY 연산에 포함되는 데이터의 크기가 줄어든다. 이는 성능을 향상할 수 있다.
TIP. SQL Query 실행 순서
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- LIMIT (또는 OFFSET)
6. 3개 이상의 테이블을 INNER JOIN 할 때는, 가장 큰 테이블을 FROM 절에, 나머지 테이블은 작은 순서대로 INNER JOIN 절에 배치하자.
// 개선 전
SELECT e.name, d.name department, p.name project
FROM projects p
INNER JOIN departments d ON p.department_id = d.id
INNER JOIN employees e ON e.department_id = d.id;
// 개선 후
SELECT e.name, d.name department, p.name project
FROM employees e
INNER JOIN departments d ON e.department_id = d.id
INNER JOIN projects p ON p.department_id = d.id;
개선 전 쿼리는 projects 테이블을 먼저 FROM 절에 배치하고 departments와 employees 테이블을 조인한다. 큰 테이블(예: projects)을 먼저 조인하면 많은 데이터를 처리해야 하므로 성능이 저하될 수 있다.
개선 후 쿼리는 employees 테이블을 먼저 FROM 절에 배치하고 departments와 projects 테이블을 조인한다. 작은 테이블(예: employees)을 먼저 처리하여 데이터 양을 줄이면, 이후 조인에서 처리할 데이터가 적어져 성능이 향상될 수 있다.
여러 테이블을 조인할 때, 큰 테이블을 FROM 절에 배치하고 작은 테이블을 INNER JOIN 절에 배치하는 것이 좋다. 이는 쿼리 플래너가 최적의 실행 계획을 세우는 데 도움이 되며, 성능을 최적화하는 데 중요한 역할을 할 수 있다.
7. OR 연산자 대신 UNION 연산자를 사용한다.
// 개선 전
SELECT *
FROM employees
WHERE department = 'Marketing' OR department = 'IT';
// 개선 후
SELECT *
FROM employees
WHERE department = 'Marketing'
UNION
SELECT *
FROM employees
WHERE department = 'IT';
개선 전 쿼리의 OR 연산자는 여러 값을 동시에 찾아야 하기 때문에 인덱스를 효율적으로 사용할 수 없게 된다. 이로 인해 데이터베이스는 전체 데이터를 스캔해야 하는 상황이 벌어질 수 있다.
개선 후 쿼리는 각 쿼리를 독립적으로 최적화하고 실행할 수 있다. department = 'Marketing'와 department = 'IT'는 각각 인덱스를 통해 빠르게 처리될 수 있다. 그러고 나서 UNION이 두 결과를 합치는 것이죠. 이 과정에서 중복된 결과는 자동으로 제거된다.
만약 중복이 없다는 것이 확실하다면 UNION ALL을 사용해 중복 제거 단계를 건너뛰고 성능을 더 높일 수도 있다. 하지만 대부분의 경우 정확한 결과를 위해선 UNION이 권장된다.
어떻게 개선했나
성능 저하의 핵심은 총 행 수 계산과 데이터 페이징을 별도의 데이터베이스 호출로 처리하는 로직 부분이다.
결론적으로, 총 행 수 계산과 데이터 페이징을 결합하여 단일 쿼리 스코프에서 처리하고, 특정 필터에 관련된 쿼리 로직에 인덱스를 적용하면 성능 개선을 기대할 수 있다.
기존 로직의 의도를 해치지 않는 선에서 GORM을 도입한 후 리팩토링을 진행했고, 아래에 간략한 예제 코드 일부를 공유한다.
결합된 쿼리 (개선)
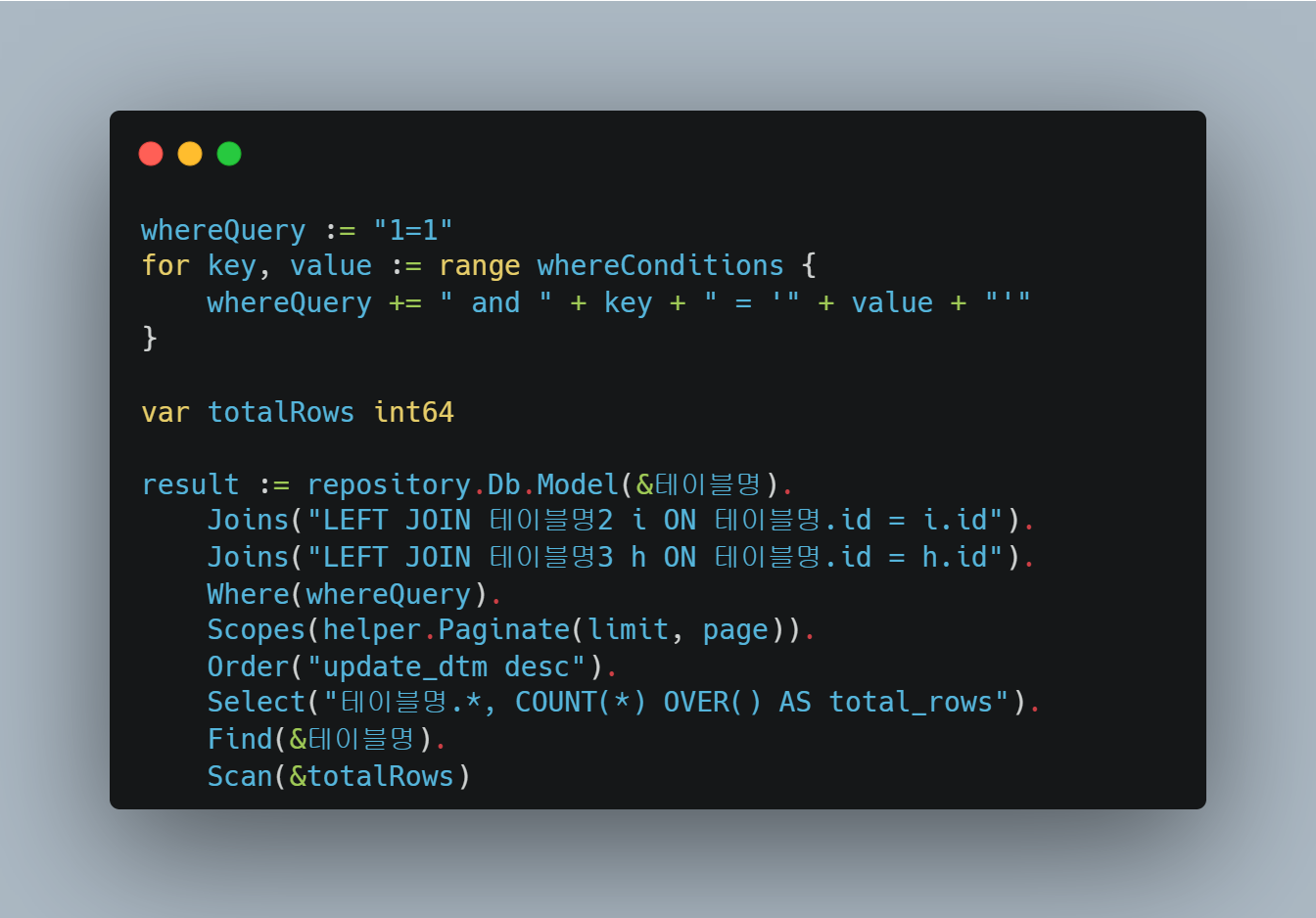
개선 전

개선 후

- 5,850ms -> 23ms, 약 254배의 개선
추가적으로 가독성을 위해 도입한 방법들을 아래에 간략하게 예제 코드 일부를 공유한다.
Where 조건을 위한 Map 사용

WHERE 조건 최적화

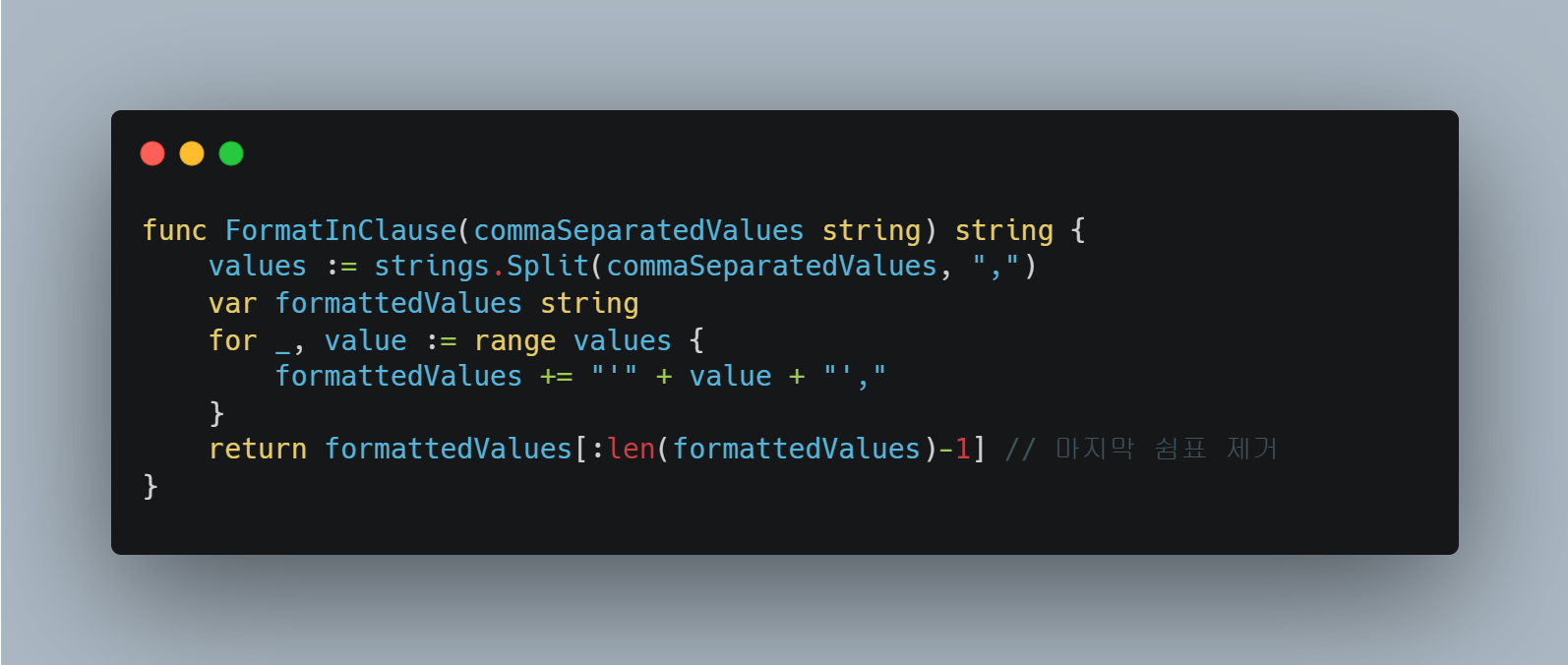
헬퍼 함수 도입
출처
https://docs.singlestore.com/cloud/query-data/query-tuning/
SingleStore Helios · SingleStore Documentation
SingleStore is a modern relational database for cloud and on-premises that delivers immediate insights for modern applications and analytical systems. Book a demo or trial today!
docs.singlestore.com
https://blog.devart.com/how-to-optimize-sql-query.html
SQL Query Optimization: 12 Useful Performance Tuning Tips and Techniques
Read the tutorial to learn more about SQL Server performance tuning best practices that help greater improve SQL Server query optimization.
blog.devart.com
SQL 쿼리 성능 최적화를 위한 튜닝 팁 6가지 (Query Optimization) (heartcount.io)
SQL 쿼리 성능 최적화를 위한 튜닝 팁 6가지 (Query Optimization)
보다 효율적인 데이터 검색 및 추출을 위해 필요한 SQL 쿼리 튜닝 방법을 알려 드려요. 실무에서 더 빠르고 효과적으로 데이터를 처리할 수 있도록 하는 꿀팁 6가지에 대해 알아 보세요.
community.heartcount.io
'Dev > DataBase' 카테고리의 다른 글
| 『DataBase』 Oracle SQL 중급 문법 (1) | 2024.11.18 |
|---|---|
| 『DataBase』 Oracle SQL 기초 문법 (2) | 2024.11.18 |
| 『DataBase』 MyBatis 문법 (0) | 2024.11.01 |
| 『DataBase』 MyBatis 내부 구조 (0) | 2024.11.01 |
| 『DataBase』 대용량 데이터를 마이그레이션 할 때 무엇을 고려해야 할까 1️⃣편 (0) | 2024.08.20 |



