Oracle SQL 기초 문법에 이어서 Oracle 중급 문법을 살펴보자.
기초 문법에서 Oracle에서 제공해 주는 기본적인 내장 함수들 몇 개를 살펴봤다.
중급 문법에서는 실질적으로 실무에서 자주 사용하는 문법에 대해 알아보자.

GROUP BY
GROUP BY 절은 쿼리 결과를 지정한 표현식(expression)에 따라 그룹으로 묶어 집계 작업을 수행할 때 사용한다.
각 그룹에 대해 하나의 행을 반환하며 집계 함수와 함께 사용하여 그룹별 통계 값을 얻을 수 있다.
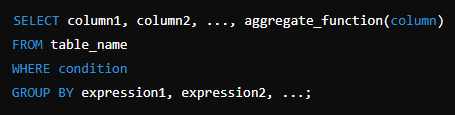

department_id별로 그룹화한 후 HAVING 절을 사용하여 평균 급여가 5000 이상 인 부서만 선택한다.
GROUP BY 확장 기능
Oracle SQL은 그룹화 및 집계 작업을 더욱 유연하게 수행할 수 있도록 ROLLUP, CUBE, GROUPING SETS 등의 확장 기능을 제공한다.
ROLLUP

- ROLLUP은 지정한 표현식의 계층 구조에 따라 소계와 총계를 계산한다.
- 예를 들어, ROLLUP (a, b, c)는 다음과 같은 집계를 생성한다.
- (a, b, c)
- (a, b)
- (a)
- ()
CUBE

- CUBE는 지정한 표현식의 모든 조합에 대한 집계를 계산한다.
- 예를 들어, CUBE (a, b)는 다음과 같은 집계를 생성한다.
- (a, b)
- (a)
- (b)
- ()
GROUPING SETS

- GROUPING SETS는 그룹화를 원하는 표현식의 집합을 직접 지정할 수 있다.
- 예를 들어, GROUPING SETS ( (a, b), (c), () )는 다음과 같은 집계를 생성한다.
- (a, b)
- (c)
- ()
GROUPING 함수

- GROUPING(column_name)은 해당 열이 그룹화에 포함되었는지를 확인한다.
- 포함되면 0을 반환하고, 포함되지 않으면 1을 반환한다.
- 소계와 총계를 구분하거나 NULL 값을 처리할 때 사용된다.
HAVING
HAVING 절은 GROUP BY로 그룹화된 결과에 조건을 적용할 때 사용한다.
WHERE 절은 그룹화 이전에 개별 행에 조건을 적용하는 반면, HAVING 절은 그룹화된 결과에 조건을 적용한다.

JOIN
JOIN은 여러 테이블의 데이터를 결합하여 조회할 때 사용한다.
일반적으로 테이블 간의 관계(예: 외래 키)를 기반으로 조인을 수행하지만 특정 조건에 따라 조인할 수도 있다.
| INNER JOIN | 두 테이블에서 조인 조건을 만족하는 행만 반환 |  |
| LEFT OUTER JOIN (= LEFT JOIN) |
왼쪽 테이블의 모든 행과 조인 조건을 만족하는 오른쪽 테이블의 행을 반환 |  |
| RIGHT OUTER JOIN (= RIGHT JOIN) |
오른쪽 테이블의 모든 행과 조인 조건을 만족하는 왼쪽 테이블의 행을 반환 | |
| FULL OUTER JOIN | 두 테이블의 모든 행을 반환하며, 조인 조건을 만족하지 않는 경우 NULL로 표시 | |
| CROSS JOIN | 두 테이블의 모든 조합을 반환 |  |
SubQuery
서브쿼리는 다른 쿼리 내에 포함된 쿼리다.
서브쿼리를 사용하여 복잡한 데이터를 한 번에 조회하거나 조건을 정의할 수 있다.

| 단일 행 서브쿼리 | 하나의 행을 반환 |
| 다중 행 서브쿼리 | 여러 행을 반환 |
| 비상관 서브쿼리 | 메인 쿼리와 독립적으로 실행 |
| 상관 서브쿼리 | 메인 쿼리의 각 행마다 서브쿼리가 실행 |
WITH
WITH 절을 사용하면 서브쿼리에 이름을 부여하여 재사용하거나 복잡한 쿼리를 단순화할 수 있다.
이는 공통 테이블 표현식(CTE, Common Table Expression)이라고도 한다.

- dept_avg_salary 서브쿼리는 부서별 평균 급여를 계산한다.
- 메인 쿼리는 직원의 급여와 부서별 평균 급여를 비교하여 평균 이상 인 직원을 조회한다.
집합 연산자 (UNION, INTERSECT, MINUS)
집합 연산자를 사용하여 여러 쿼리의 결과를 결합하거나 비교할 수 있다.
| UNION ALL | 두 쿼리의 결과를 결합 (중복 허용) |
| UNION | 두 쿼리의 결과를 결합하고 중복된 행을 제거 |
| INTERSECT | 두 쿼리의 결과에서 공통된 행만 반환 |
| MINUS | 첫 번째 쿼리의 결과에서 두 번째 쿼리의 결과를 제외한 행을 반환 |

- UNION을 사용하여 두 쿼리의 결과를 결합하고 중복된 행을 제거
- 급여가 10000 이상이거나 커미션이 있는 직원을 조회
분석 함수
분석 함수는 집계 함수의 확장 기능으로 데이터 그룹을 변경하지 않고 전체 데이터에 대한 계산을 수행한다.
OVER 절을 사용하여 분석 함수를 지정한다.

| OVER | 분석 함수를 지정 |
| PARTITION BY | 데이터를 그룹화 (옵션) |
| ORDER BY | 계산을 수행할 순서를 지정 (옵션) |
| WINDOWING | 윈도우 범위를 지정 (옵션) |

- RANK() 분석 함수를 사용하여 부서별 급여 순위를 계산한다.
- PARTITION BY department_id로 부서별로 데이터를 그룹화한다.
- ORDER BY salary DESC로 급여 순위를 매긴다.
페이지네이션 및 검색 쿼리
Oracle 12c부터는 OFFSET과 FETCH 절을 지원하여 페이징 쿼리를 쉽게 작성할 수 있다.

- OFFSET 10 ROWS로 처음 10개의 행을 건너뛴다.
- FETCH NEXT 10 ROWS ONLY로 그다음 10개의 행을 가져온다.
- 결과적으로 11번째부터 20번째까지의 행을 조회한다.
바인드 변수를 사용하여 동적 페이지네이션을 구현하는 방법은 다음과 같다.

- :page_size: 페이지당 표시할 행의 수를 나타내는 바인드 변수
- :page_number: 조회할 페이지 번호를 나타내는 바인드 변수
- OFFSET 절에서 :page_size * (:page_number - 1)를 사용하여 건너뛸 행의 수를 계산
- FETCH NEXT :page_size ROWS ONLY로 한 페이지 분량의 행을 가져온다.
검색 기능을 구현할 때는 사용자 입력에 따라 조건을 동적으로 변경해야 한다.
이를 위해 동적 SQL이나 조건적인 WHERE 절을 사용한다.

바인드 변수 :search_name을 사용하여 검색어를 입력받는다.
계층형 쿼리
계층형 쿼리는 트리 구조를 가진 데이터를 조회할 때 사용한다.
Oracle SQL에서는 CONNECT BY 절을 사용하여 계층 구조를 정의한다.

- START WITH: 트리의 루트 노드를 정의한다.
- CONNECT BY: 부모-자식 관계를 정의한다.
- PRIOR 연산자를 사용하여 부모와 자식을 지정한다.
- NOCYCLE: 순환 참조를 방지한다.

- manager_id IS NULL인 직원(최고 관리자)을 루트 노드로 시작한다.
- PRIOR employee_id = manager_id로 직원과 그 관리자의 관계를 정의한다.
- LEVEL은 계층의 깊이를 나타낸다.
위 쿼리의 결과는 아래와 같다.

PIVOT, UNPIVOT
PIVOT과 UNPIVOT 연산자는 행과 열을 변환하여 데이터의 형태를 바꿀 때 사용한다.
PIVOT

- 내부 쿼리에서 필요한 열을 선택한다.
- PIVOT 절을 사용하여 job_id의 값들을 열로 변환하고 employee_id의 수를 계산한다.

UNPIVOT
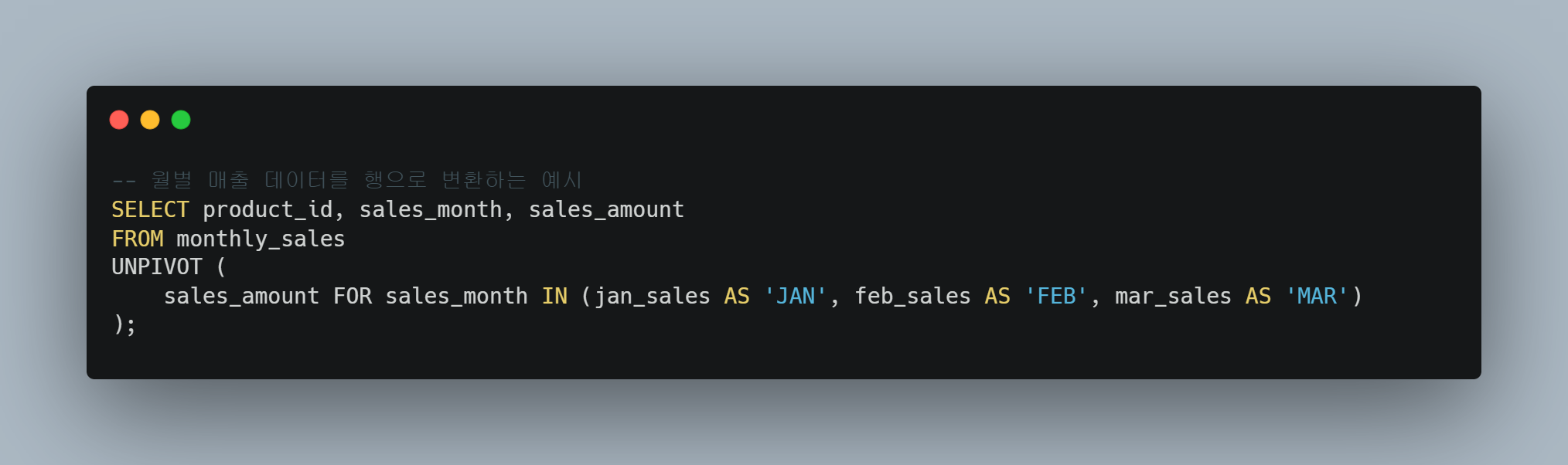
- monthly_sales 테이블에서 각 월의 매출 열을 행으로 변환한다.
- sales_month 열에 월 정보를 담고, sales_amount 열에 매출 금액을 담는다.
'Dev > DataBase' 카테고리의 다른 글
| 『DataBase』 Oracle SQL & MyBatis Mapper 부먹 (1) | 2024.12.22 |
|---|---|
| 『DataBase』 Oracle SQL 기초 문법 (2) | 2024.11.18 |
| 『DataBase』 MyBatis 문법 (0) | 2024.11.01 |
| 『DataBase』 MyBatis 내부 구조 (0) | 2024.11.01 |
| 『DataBase』 대용량 데이터를 마이그레이션 할 때 무엇을 고려해야 할까 1️⃣편 (0) | 2024.08.20 |



